## NN(神经网络)
- 神经网络是模拟人脑神经元结构,通过学习样本数据,自动调整神经元之间的连接权重,从而实现输入到输出的映射关系。
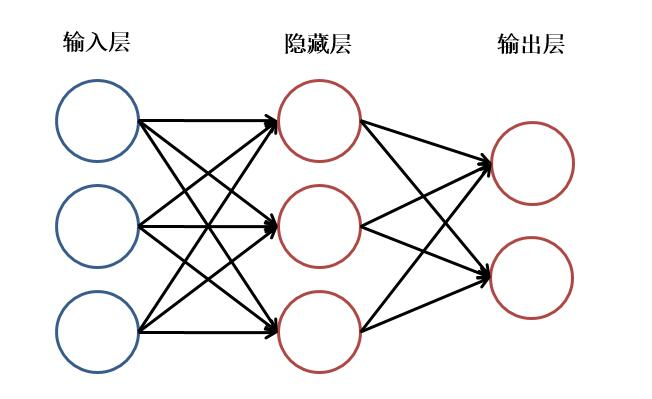
- 神经网络是一种计算模型,由多个**神经元**组成,每个神经元接受一组输入,通过加权求和并加上偏置,然后通过**激活函数**输出结果。
- 什么叫做神经元
- 本质是**带参数的计算单元**:
- 每个神经元保存自己的**权重向量**和**偏置值**(好比每个小学生有一本记录如何给不同线索打分的笔记本)
- 计算过程分两步:
1. **加权求和**:`z = (输入1×权重1) + ... + (输入n×权重n) + 偏置`(小学生把前一层所有同学的报告按自己的评分标准汇总)
2. **激活函数处理**:`输出 = 激活函数(z)`(根据汇总结果决定如何向上汇报)
| 层级 | 计算原理 | 小学生团队比喻 | 数学示例 |
| ---------- | ---------------------- | ---------------------------------- | ------------------------------ |
| 输入层 | 像素值矩阵 | 全班同学把画纸分成小格子描点 | [0.2, 0.7, ...] (归一化像素) |
| 卷积层1 | 5×5滤波器扫描特征 | 第1组5人小队用不同形状探照灯找线条 | conv2d(x, kernel)+bias |
| 全连接层 | 矩阵乘法组合特征 | 第2组20人分析形状组合(三角形=斜边+顶点) | 0.7*h1 + 0.3*h2 - 1.2 = z |
| 输出层 | Softmax概率归一化 | 校长根据各小组报告投票决策 | [猫:0.85, 狗:0.15] |
- 
- 什么叫做激活函数?
- 激活函数在神经网络中扮演着“决策开关”的角色,其核心功能是通过非线性映射决定神经元是否应该被“激活”(即输出信号)
- 它的核心功能就是:
- 一、**引入非线性**
- 假设你是一个魔术师,观众给你一堆二维平面上的普通点(比如圆形、三角形),你需要在舞台上把它们变成能区分的形状(比如一只猫、一只狗)。
- 没有激活函数:你只能用直尺和橡皮擦把点连成直线或圆(线性工具),但复杂的形状(如猫的耳朵、狗的尾巴)根本画不出来。
- 有激活函数:可以把直线变成曲线、把平面变成螺旋形。比如,**ReLU**这个常用的激活函数就像一把剪刀,把负数的部分剪掉(只保留正数),让数据突然“跳跃”,从而画出异或门(XOR)这种非线性的分界线。
- 🌰:用ReLU处理螺旋数据时,原本混在一起的点会被“剪开”,分成两个簇(类似分类)。
- 二、**控制信号流动**
- 想象神经网络是一条河流,数据像水流一样从输入层流向输出层。
- 没有激活函数:河水会毫无节制地,毫无规划的到处奔涌,垃圾数据也不会被过滤,数据的流动没有方向,下游的节点可能被冲垮(梯度爆炸、数据全部往这里走)或干涸(梯度消失,数据不往这里走)。
- 有了激活函数:
- **Sigmoid/Tanh**:像一座水坝,把水流限制在0-1或-1-1之间,避免下游溢出。
- **ReLU**:像一道闸门,只允许正数通过(负数被截断),这样下游不会被“负洪水”淹没。
- 🌰 在图像识别中,ReLU能让关键特征(如边缘)被放大传递,而无关的噪声被“截断”。
- 三、**防止梯度消失/爆炸**
- 假设你开着一辆神经网络汽车,层数越深,道路就越陡峭复杂。
- 梯度消失:就像踩着刹车一直下坡,车速越来越慢(甚至停下来),后面的层学不到东西。
- 梯度爆炸:就像猛踩油门冲下悬崖,车速失控(参数值变得极大或极小),模型完全崩溃。
- **ReLU**的解决方案:在陡峭的下坡路段(正区间),ReLU的导数是1(油门保持最大),不再减速,轻松爬过深层网络的“大山”。
- 🌰 **ResNet**(深度残差网络)用ReLU和跳跃连接(可以跨跃层数,不用一层一层来),就像给汽车装了直升机桨,直接飞过深层“峡谷”。
- 四、**引入稀疏性**
- 假设神经网络是一个图书馆,每个神经元是一本本书。
- 没有稀疏性:所有书都被摊开在桌上,你找不到重点(所有神经元都活跃)。
- 有了激活函数:
- Softmax:像一个图书管理员,把最相关的几本书(概率最高的类别)举高展示,其他书堆在角落(接近0)。
- Sparsemax:更严格,只允许一本“最佳书”被选中,其他全部关闭。
- 🌰 在自然语言处理中,Softmax能让模型在“猫”“狗”“鸟”三个词中,只输出一个最可能的答案(比如“猫”),其他概率接近0。
- 损失函数的作用:
- 损失函数就是根据预测值和真实值之间的差距,来计算一个“损失值”。
- 损失值越小,说明预测值和真实值越接近,模型越好。
- 损失函数是反向传播算法的核心,它告诉模型应该怎么调整参数,才能让损失值变小。
- 过拟合:如果班主任太严格(比如要求必须和标准答案完全一致),学生会死记硬背:
- 被在训练集上训练过的猫,就只认猫,其他动物都不认(泛化能力差)
- 欠拟合:如果班主任心太软(比如只要大致像就行),学生会敷衍:
- 把所有四只脚的动物都喊成猫(狗、老虎、兔子统统算错)
| 场景 | 过拟合现象 | 欠拟合现象 |
|-----------------|---------------------------------------------------|---------------------------------|
| 手写数字识别(MNIST) | 模型准确率达99% on training set,但测试集仅85% | 训练集准确率70%,测试集72% |
| 房价预测 | 模型完美穿过所有训练数据点 | 模型是一条水平直线,忽略面积、房龄等因素 |
```
1. 过拟合的深层原因
模型复杂度过高:当模型参数过多(如深度神经网络层数过深)时,会过度拟合训练数据的噪声和**偶然规律**。
验证集表现差:在测试集上准确率显著低于训练集(如学生仅记住特定猫的特征,却无法识别新品种)。
解决方案:正则化(L1/L2)、Dropout、早停法、数据增强等。
2. 欠拟合的深层原因
模型复杂度过低:模型缺乏足够参数捕捉数据规律(如线性模型拟合非线性数据)。
特征工程不足:未提取有效特征(如仅用"四条腿"区分猫,忽略瞳孔形状、尾巴特征)。
解决方案:增加模型层数、神经元数量、添加多项式特征等。
```
- 优化器的作用:
- 优化器就是根据损失函数的梯度,来调整模型参数,以最小化损失值。
- 优化器有很多种,比如SGD(随机梯度下降)、Adam、RMSprop等等。
- 优化器的选择和调整,对模型的训练效果有很大影响。
## RNN(循环神经网络)
嗯,用户问我知不知道RNN,还问它的原理是什么。首先,RNN是循环神经网络,对吧?我记得它是用来处理序列数据的,比如时间序列或者自然语言处理的任务。不过具体细节可能得慢慢理清楚。
首先,RNN的全称是Recurrent Neural Network,循环神经网络。和普通的前馈神经网络不同,RNN有循环的结构,可以处理变长的序列数据。比如,处理句子的时候,每个词逐个输入,而RNN能记住之前的信息,对吧?
那它的原理是什么呢?我记得每个时间步会处理一个输入,并且有一个隐藏状态传递给下一个时间步。这个隐藏状态相当于网络的记忆,保存了之前的信息。比如,处理句子中的某个词时,隐藏状态会包含前面词的上下文信息。
不过具体结构是怎样的呢?每个时间步的输入包括当前的输入数据和上一个时间步的隐藏状态。然后通过某种计算得到当前步的输出和新的隐藏状态。可能有一个权重矩阵用于输入,另一个用于隐藏状态,再加上激活函数,比如tanh函数,对吧?
比如,数学表达式可能是h_t = tanh(W_x * x_t + W_h * h_{t-1} + b),然后输出可能是y_t = softmax(W_y * h_t + b_y)。不过是不是这样呢?可能有不同的变体,比如Elman网络和Jordan网络,结构上有些区别。
不过RNN有什么问题呢?我记得梯度消失或梯度爆炸的问题,尤其是在处理长序列时,因为反向传播要通过时间展开,导致梯度难以传递到较早的时间步。所以后来有了LSTM和GRU这些改进结构,通过门控机制来控制信息的流动。
那用户可能还想知道RNN的应用场景,比如语言模型、机器翻译、语音识别等。但为什么现在很多地方被Transformer取代了呢?因为Transformer用了自注意力机制,能更好地捕捉长距离依赖,而且并行计算效率更高。不过RNN作为基础模型,理解它还是很重要的。
另外,RNN的训练方式是什么?使用BPTT,即随时间反向传播,类似于标准反向传播,但需要处理时间维度的展开。这可能带来计算上的复杂性,尤其是长序列时内存消耗大。
用户可能还有疑问,RNN的不同变体之间的区别是什么?比如Simple RNN、LSTM、GRU。或者RNN在序列建模中的具体优势,比如处理变长输入,保持时间上的上下文信息。
总结一下,回答RNN需要包括定义、结构原理、数学表达式、优缺点、常见变体和应用场景。同时要提到梯度问题以及后续的改进模型。确保解释清楚循环连接的作用,以及如何处理序列数据的依赖性。
循环神经网络(RNN,Recurrent Neural Network)是一种专门用于处理**序列数据**的神经网络模型。其核心思想是通过**循环连接**捕捉序列中的时序依赖关系,适用于自然语言处理、时间序列预测、语音识别等任务。
---
### **RNN 的核心原理**
1. **循环结构**:
- RNN 的每个时间步(Time Step)接收**当前输入**和**前一时刻的隐藏状态**,生成**当前输出**和**新的隐藏状态**传递给下一时间步。
- 这种循环结构使网络具有“记忆”能力,能够利用历史信息。
2. **数学表达**:
- **隐藏状态(Hidden State)**:
- $$h_t = \sigma(W_h h_{t-1} + W_x x_t + b)\ $$
- $h_t$:当前时刻的隐藏状态
- $x_t$:当前时刻的输入
- $W_h, W_x$:权重矩阵
- $\sigma$:激活函数(如 tanh 或 ReLU)
- **输出(Output)**:
$$ y_t = \text{Softmax}(W_y h_t + b_y)$$
- 输出可能是分类结果(如词的概率分布)或数值预测。
---
### **RNN 的工作流程**
1. **初始化隐藏状态** $h_0$(通常为全零)。
2. 对序列中的每个元素 $x_t$:
- 计算当前隐藏状态 $h_t$(融合当前输入和前一状态)。
- 基于 $h_t$ 生成输出 $y_t$。
3. **信息传递**:隐藏状态 $h_t$ 传递到下一时间步,形成循环。
---
### **RNN 的优缺点**
- **优点**:
- 直接处理**变长序列**(如句子、时间序列)。
- 理论上能捕捉任意长度的时序依赖。
- **缺点**:
- **梯度消失/爆炸**:长序列训练时,梯度难以有效传递到早期时间步(LSTM、GRU 通过门控机制解决)。
- **短期记忆**:难以捕捉长期依赖关系。
- **计算效率低**:无法并行处理序列(与 Transformer 对比)。
---
### **RNN 的应用场景**
1. **自然语言处理(NLP)**:
- 文本生成、机器翻译(早期模型)、情感分析。
2. **时间序列预测**:
- 股票价格预测、天气预测。
3. **语音处理**:
- 语音识别、语音合成。
### **微信聊天中的 RNN**
假设你正在和朋友用微信聊天,每次回复都要**结合之前的对话内容**。你的大脑就像一个 RNN,既要看新消息,又要记住之前的聊天记录。
#### **1. 对话流程(时间步)**
- **输入(Input)**:朋友刚发来的新消息(比如:“晚上吃火锅吗?”)。
- **隐藏状态(Hidden State)**:你大脑里记住的**之前的聊天内容**(比如昨天他说“最近上火”)。
- **输出(Output)**:你根据新消息和记忆生成的回复(比如:“别吃火锅了,你昨天说上火了,换清淡的吧?”)。
#### **2. 工作原理(循环步骤)**
- **第1条消息**:朋友说“今天好热”,你回复“是啊,记得开空调”,并记住“天气热”。
- **第2条消息**:朋友说“下午去打球?”,你结合“天气热”回复“太热了,晚点再去”。
- **第10条消息**:朋友说“晚上吃火锅吗?”,此时你已经聊了很多其他话题(比如工作、电影),可能**忘记之前提过“天气热”**,直接回复“好呀!”(这就是 RNN 的短期记忆问题)。
#### **3. 核心特点**
- **记忆依赖**:每次回复都基于**当前消息 + 之前的记忆**。
- **记忆衰减**:如果聊天很长,早期的信息(如“天气热”)会被逐渐覆盖,导致回复不连贯。
---
### **RNN 的缺陷**
- **金鱼脑**:聊到第100条消息时,你早就忘了朋友第1条说过“我对海鲜过敏”,结果建议去吃海鲜火锅(长期依赖丢失)。
- **混乱的上下文**:如果朋友突然切换话题(比如从“火锅”跳到“编程问题”),你可能还在用“火锅”相关的记忆回复,导致答非所问(梯度传播问题)。
---
### **再举个实际例子**
**任务:续写故事**
- **普通 RNN 作者**:
- 开头:“公主被恶龙抓走了,骑士带上剑出发……”
- 中间写了100句战斗细节,结果结局写成:“骑士用枪打败了龙”(忘了开头带的**是剑不是枪**)。
## LSTM
好的,用户现在想要用类似之前介绍的RNN的通俗比喻方式来理解LSTM。之前用户对快递和微信聊天的例子不太满意,后来换成了微信聊天的例子,用户觉得不错,现在希望用同样的方式来讲解LSTM。
首先,我需要回顾LSTM的核心机制。LSTM通过引入遗忘门、输入门和输出门,以及细胞状态来解决RNN的长期依赖问题。细胞状态是关键,它像一条传送带,能够在序列处理过程中保持信息。三个门控结构负责调节信息的保留和遗忘。
接下来,要找一个贴近生活的比喻。用户之前喜欢微信聊天的例子,所以可能需要延续这个场景,或者换另一个日常情境。比如,可以比喻为一个有经验的大厨做饭,或者一个学生记笔记。需要确保比喻能够直观地解释门控机制和细胞状态的作用。
用户可能希望比喻既能说明LSTM的记忆能力,又能解释各个门的作用。比如,在之前的RNN比喻中,RNN像普通人聊天容易忘记,而LSTM则像有备忘录的秘书。现在需要详细展开这个秘书是如何工作的,即三个门如何控制信息的遗忘、更新和输出。
另外,用户可能对技术术语不太熟悉,需要用简单易懂的语言,避免专业术语。同时,要对比RNN,突出LSTM的优势,比如长期记忆、选择性记住和忘记等。
需要检查比喻是否准确传达了LSTM的关键点:细胞状态的长期信息传递,遗忘门决定丢弃什么信息,输入门决定更新什么新信息,输出门基于当前状态产生输出。同时,要说明这些门如何协同工作,解决梯度消失或爆炸的问题。
可能还需要举一个具体的例子,比如续写故事时,LSTM如何记住关键细节,而RNN会忘记。或者像聊天中的备忘录功能,记录重要信息,忽略无关内容。
最后,确保回复结构清晰,分点说明,使用emoji和适当的排版,保持与之前回复一致的风格,让用户容易理解和记忆。
好的!用「微信聊天」的比喻来解释 LSTM,再搭配一个厨房做菜的例子,保证通俗易懂~ 😄
---
### **比喻一:LSTM 像一位「严谨的聊天达人」**
假设你是一个记忆力超强的朋友,每次微信聊天时都会用**三个小本子**记录信息,确保不遗漏重要细节:
#### **1. 核心装备:三个「小本子」+「备忘录」**
• **备忘录(细胞状态)**:
一个长期保存核心信息的本子(比如“朋友对海鲜过敏”),只记录关键内容,不容易被修改。
• **三个小本子(三个门控)**:
• **遗忘本子(遗忘门)**:决定哪些旧信息需要**删除**(比如“昨天聊的天气”不重要,划掉)。
• **记录本子(输入门)**:判断当前消息哪些需要**写进备忘录**(比如“朋友刚说对花生过敏”)。
• **输出本子(输出门)**:根据备忘录和当前消息,生成回复(比如结合“过敏”和“火锅”,建议不吃花生酱)。
#### **2. 工作流程(做一顿火锅)**
1. **遗忘本子先清理**:
• 朋友说:“今天去哪吃火锅?”
• 你翻开遗忘本子,划掉无关旧信息(比如上周聊的电影)。
2. **记录本子更新备忘录**:
• 朋友补充:“我不吃羊肉。”
• 你判断这是重要信息,写进备忘录:“不吃羊肉”。
3. **输出本子生成回复**:
• 结合备忘录里的“不吃羊肉”和当前消息,你回复:“那我们去吃潮汕牛肉火锅,不点羊肉!”
4. **长期记忆保留**:
• 即使聊了100条消息,备忘录里的“不吃羊肉”依然保留,下次推荐餐厅时自动避开羊肉。
---
### **比喻二:LSTM 像「智能厨房做菜」**
想象你是一个大厨,厨房里有**三个智能助手**帮你管理做菜流程:
#### **1. 核心道具:**
• **主厨台(细胞状态)**:一条传送带,专门传递最重要的食材(比如“鸡汤”),中途不会被随意替换。
• **三个智能助手(三个门控)**:
• **食材过滤器(遗忘门)**:丢掉没用的食材(比如发霉的洋葱)。
• **新食材质检员(输入门)**:检查新食材是否合格(比如新鲜的牛肉),合格后放到主厨台上。
• **调味师(输出门)**:根据主厨台的食材,决定最终口味(比如加多少盐)。
#### **2. 做菜流程(炖一锅汤)**
1. **食材过滤器开工**:
• 你准备炖汤,过滤器自动丢掉过期的香料(遗忘无用信息)。
2. **新食材质检员上岗**:
• 你加入新鲜排骨,质检员判断这是优质食材,放上主厨台(更新细胞状态)。
3. **主厨台传递核心味道**:
• 排骨和之前保留的鸡汤一起慢炖,味道越来越浓(长期记忆保留)。
4. **调味师最后加工**:
• 汤炖好后,调味师根据当前味道加盐,盛出一碗完美的汤(输出结果)。
---
### **LSTM 的终极优势**
• **长期记忆**:备忘录(细胞状态)专门保存关键信息,避免像普通RNN一样“聊着聊着就忘了”。
• **选择性记忆**:
• **忘掉废话**(遗忘门:“昨天的天气”不重要→删除)。
• **记住重点**(输入门:“对花生过敏”→写进备忘录)。
• **灵活输出**(输出门):根据记忆和当前情况,生成合理回复。
---
### **对比普通RNN和LSTM**
• **普通RNN朋友**:
• 金鱼脑,聊到第10句就忘了开头说过“对海鲜过敏”,结果推荐海鲜火锅。
• **LSTM朋友**:
• 备忘录里永远记着“过敏”,哪怕聊了100句,依然提醒你:“别点海鲜!”
---
### **现实中的LSTM应用**
1. **机器翻译**:
LSTM像严谨的翻译官,记住整句话的主语(比如“他”),避免翻译成“她”。
2. **股票预测**:
备忘录里长期记录经济周期规律,结合最新数据预测趋势。
3. **写小说**:
即使故事写了10万字,主角的名字和关键伏笔依然不会搞错。
---
LSTM是一个“记忆力超强且会抓重点”的智能助手,靠三个小本子(门控)和一张备忘录(细胞状态),完美解决了普通RNN的“健忘症”! 🚀
### LSTM是如何记忆哪些要保留哪些不要的呢?
假设你是一个LSTM聊天机器人,朋友和你聊天的每一条消息,你都需要决定**记住什么**、**忘掉什么**。但你有一个「小秘书」(遗忘门和输入门)帮你做决策:
#### **1. 小秘书的决策工具:打分器(Sigmoid函数)**
• 小秘书手里有一个神奇的「打分器」,可以把任何信息的重要性打成 **0到1分**:
• **0分**:完全遗忘(比如“朋友昨天说天气热”)。
• **1分**:必须记住(比如“朋友对海鲜过敏”)。
• **0.5分**:暂时留着但可能以后删掉(比如“朋友喜欢奶茶”)。
#### **2. 如何判断遗忘和保留?**
• **步骤1:看上下文(当前输入 + 之前的记忆)**
小秘书每次收到新消息(比如“今晚吃海鲜吗?”),会结合两个信息:
• **当前输入**:新消息内容(“海鲜”)。
• **之前的记忆**:之前的聊天记录(比如备忘录里记着“对海鲜过敏”)。
• **步骤2:用「遗忘门」打分**
小秘书用「遗忘门」给之前的记忆打分:
• 如果新消息是“海鲜”,而备忘录里有“过敏”,小秘书会判断:“过敏是重点,遗忘门打1分→必须保留”。
• 如果之前的记忆是“喜欢奶茶”,而新消息是“吃火锅”,小秘书可能打0.1分→几乎遗忘。
• **步骤3:用「输入门」筛选新信息**
同时,小秘书用「输入门」给新消息打分:
• 如果朋友说“我对花生也过敏”,输入门打1分→写进备忘录。
• 如果朋友说“今天穿蓝衬衫”,输入门打0分→直接忽略。
---
### **厨房里的「食材质检员」**
想象你在厨房做菜,LSTM就像一个智能质检流程:
#### **1. 质检员的工作(遗忘门和输入门)**
• **遗忘门质检员**:检查冰箱里的旧食材(之前的记忆),决定哪些要丢掉。
• 烂掉的蔬菜(无用信息)→ 丢进垃圾桶(打0分)。
• 新鲜的牛肉(重要信息)→ 保留(打1分)。
• **输入门质检员**:检查新买的食材(当前输入),决定哪些放进冰箱。
• 活蹦乱跳的鱼(关键新信息)→ 存进冰箱(打1分)。
• 发霉的面包(无关信息)→ 直接扔掉(打0分)。
#### **2. 质检标准从哪来?**
• 这些「质检员」的判断能力不是天生的,而是通过**大量训练**学到的:
• 比如反复练习做菜1000次后,每次做错,质检员都会由于损失函数被罚款,随后质检员学会:“牛肉比洋葱重要,发霉的必须扔”。
• 在深度学习中,就是模型通过数据训练,自动学习到哪些信息该保留(比如“过敏”比“天气”更重要)。
---
### **数学公式(超简版)**
1. **遗忘门打分**:
$$
f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
$$
• $\sigma$是Sigmoid函数,输出0~1之间的分数。
• $W_f$和 $b_f$ 是训练学到的参数,决定如何给旧记忆打分。
2. **输入门打分**:
$$
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
$$
• 同样用Sigmoid判断新信息的重要性。
3. **更新细胞状态(备忘录)**:
$$
C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t
$$
• 旧记忆按遗忘门分数保留 $f_t$ $\cdot$ $C_{t-1}$。
• 新信息按输入门分数加入$i_t$ $\cdot$ $\tilde{C}_t$。
---
### **现实例子:聊天中的过敏提醒**
1. **场景**:朋友说:“我对海鲜过敏”(第1条消息)。
2. **LSTM 处理**:
• 输入门检测到“过敏”是关键词→打分接近1,写入备忘录。
• 后续聊天中,遗忘门每次看到备忘录里的“过敏”→打1分,坚决保留。
3. **结果**:即使聊了100条其他消息,当你建议“去吃海鲜”时,LSTM依然能根据备忘录阻止你。
---
### **为什么LSTM能学会这些判断?**
• **训练过程**:通过大量数据(比如上万条聊天记录)反复调整参数:
• 如果模型忘记“过敏”导致推荐错误,系统会抽他一鞭子,逼他下次加强记忆。
• 如果模型记住了无用信息(比如“穿蓝衬衫”),系统也会系统会抽他一鞭子,让他学会遗忘。
• **最终效果**:模型自动发现“过敏”“疾病”“地址”等关键信息需要长期保留,而“天气”“衣服颜色”等可以遗忘。
---
### **总结**
LSTM的「遗忘和保留」本质是靠两个门控:
1. **遗忘门**:给旧记忆打分→ “留多少旧知识”。
2. **输入门**:给新信息打分→ “加多少新知识”。
3. **核心秘密**:这些打分规则是模型从数据中自己学到的,就像人类通过经验知道“过敏比天气重要”。
## GRU
### **GRU 的核心原理**
GRU 通过**门控机制**控制信息的流动,决定保留或丢弃哪些历史信息,主要包含两个关键门:
1. **更新门(Update Gate)**
• 作用:决定当前时刻有多少历史信息需要保留,多少新信息需要加入。
• 类似于“记忆开关”,帮助模型选择性地记住长期依赖。
2. **重置门(Reset Gate)**
• 作用:决定哪些历史信息需要被忽略,以更灵活地结合当前输入。
• 用于过滤无关的过去信息,关注当前输入的关键部分。
通过这些门控,GRU 可以动态调整记忆内容,有效缓解梯度消失/爆炸问题。
---
### **GRU 的典型应用场景**
1. **自然语言处理(NLP)**
• 机器翻译、文本生成、情感分析(如生成连贯的句子或翻译结果)。
2. **语音识别**
• 将音频信号转换为文本,捕捉语音中的时序特征。
3. **时间序列预测**
• 股票价格预测、天气预测、能耗预测等(利用历史数据预测未来趋势)。
4. **推荐系统**
• 分析用户行为序列(如点击、浏览记录),预测下一次可能的操作。
5. **视频分析**
• 理解视频中的动作序列或事件发展。
---
### **GRU vs. LSTM**
• **GRU 的优势**
• 结构更简单(2个门 vs. LSTM的3个门),参数更少,训练速度更快。
• 在数据量较少或资源受限时,可能表现更优。
• **LSTM 的优势**
• 理论上有更强的长期记忆能力,适合更复杂的序列任务(如极长文本)。
• **选择建议**:两者性能通常接近,实践中需根据任务和资源做实验选择。
---
# 1. GRU的核心公式
GRU通过两个门控(更新门和重置门)动态调整隐藏状态,公式如下:
## **(1) 更新门(Update Gate)**
zt = σ(Wz ⋅ xt + Uz ⋅ ht−1 + bz)
- 作用:决定当前时刻保留多少历史信息(ht−1)和吸收多少新信息。
- 符号说明:
- xt:当前时刻的输入向量。
- ht−1:上一时刻的隐藏状态。
- Wz, Uz:权重矩阵,bz:偏置项。
- σ:Sigmoid激活函数(输出值在[0,1]之间)。
## **(2) 重置门(Reset Gate)**
rt = σ(Wr ⋅ xt + Ur ⋅ ht−1 + br)
- 作用:决定忽略多少过去的隐藏状态(ht−1),用于生成候选状态。
- 示例:若 rt ≈0,则候选状态 h~t 几乎不依赖历史信息,仅关注当前输入 xt。
## **(3) 候选隐藏状态(Candidate Hidden State)**
h~t = tanh(Wh ⋅ xt + Uh ⋅ (rt ⊙ ht−1) + bh)
- 作用:生成一个临时的“新状态”,结合当前输入和部分历史信息。
- 关键点:
- ⊙ 表示逐元素相乘(Hadamard积)。
- 重置门 rt 控制历史信息 ht−1 的保留比例。
## **(4) 最终隐藏状态(Hidden State)**
ht = (1−zt) ⊙ ht−1 + zt ⊙ h~t
- 作用:通过更新门 zt 融合历史状态 ht−1 和候选状态 h~t。
- 直观解释:
- zt ≈1:隐藏状态 ht 主要由候选状态 h~t 决定(学习新信息)。
- zt ≈0:隐藏状态 ht 几乎等于 ht−1(保留历史信息)。
# 2. 公式的物理意义
- 更新门 zt:类似于LSTM的输入门和遗忘门的结合体,平衡新旧信息。
- 重置门 rt:控制历史信息的“遗忘”程度,帮助模型聚焦于当前输入的关键部分。
- 候选状态 h~t:在重置门过滤后的历史信息基础上,生成新的潜在状态。
- 最终状态 ht:通过线性插值动态更新,避免传统RNN的梯度消失问题。
# 3. 梯度反向传播的优势
GRU的隐藏状态更新公式(ht = (1−zt) ⊙ ht−1 + zt ⊙ h~t)本质上是加法操作:
- 梯度在反向传播时,可以通过两条路径传递:
- ht−1 的路径: ∂ht−1/∂ht = (1−zt) + ...
- h~t 的路径: ∂h~t/∂ht = zt
- 优势:加法操作使得梯度不易消失(类似残差连接),适合处理长序列依赖。
# 4. GRU vs. LSTM的公式对比
| 组件 | GRU | LSTM |
|------------|--------------------|--------------------|
| 门控数量 | 2个门(更新门、重置门) | 3个门(输入门、遗忘门、输出门) |
| 状态更新 | 直接线性插值(无细胞状态) | 通过细胞状态Ct间接更新 |
| 参数数量 | 更少(约LSTM的75%) | 更多 |
| 计算效率 | 更高 | |
### 常用的场景
#### **1. 自然语言处理(NLP)**
• **文本生成**:生成连贯的句子(如聊天机器人、诗歌创作)。
• 示例:根据用户输入的前半句,自动补全后半句。
• **机器翻译**:将一种语言翻译为另一种语言。
• 示例:将英文句子翻译为中文,保留语义和语法结构。
• **情感分析**:判断文本的情感倾向(正面/负面)。
• 示例:分析社交媒体评论的情感,用于品牌舆情监控。
• **命名实体识别(NER)**:从文本中提取人名、地名、机构名等。
• 示例:从新闻文章中提取关键人物和事件信息。
---
#### **2. 语音识别与合成**
• **语音转文本**:将音频信号转换为文字。
• 示例:智能音箱(如天猫精灵、小爱同学)识别用户的语音指令。
• **语音合成**:生成自然流畅的语音。
• 示例:为电子书生成有声读物,模拟人类发音节奏。
---
#### **3. 时间序列预测**
• **金融预测**:股票价格、汇率趋势预测。
• 示例:基于历史股价数据预测未来一周的涨跌趋势。
• **气象预测**:气温、降雨量预测。
• 示例:根据过去一周的气象数据预测未来48小时的天气。
• **工业设备预测性维护**:预测设备故障时间。
• 示例:通过传感器数据预测工厂机器的故障风险。
---
#### **4. 推荐系统**
• **用户行为建模**:分析用户的点击、浏览、购买序列。
• 示例:根据用户历史观看记录推荐短视频(如抖音、YouTube)。
• **动态推荐**:实时调整推荐内容。
• 示例:电商平台根据用户当前浏览的商品推荐关联产品。
---
#### **5. 视频分析与行为识别**
• **视频内容理解**:识别视频中的动作或事件。
• 示例:监控视频中检测异常行为(如跌倒、闯入)。
• **视频生成**:生成连续的视频帧。
• 示例:根据一段文字描述生成短视频片段。
---
#### **6. 生物医学数据处理**
• **疾病预测**:基于患者历史健康数据预测疾病风险。
• 示例:通过心电图(ECG)序列数据预测心脏病发作概率。
• **蛋白质结构预测**:分析氨基酸序列的折叠模式。
---
#### **7. 能源与资源管理**
• **电力负荷预测**:预测城市或家庭的用电量。
• 示例:根据历史用电数据优化电网调度。
• **可再生能源预测**:预测太阳能、风能的发电量。
• 示例:通过天气数据预测未来24小时的风力发电效率。
---
### **为什么选择 GRU 而不是其他模型?**
• **中等长度序列**:GRU 在序列长度适中时表现高效(如几十到几百步)。
• **资源有限场景**:相比 LSTM,GRU 参数更少,训练更快,适合移动端或实时系统。
• **避免过拟合**:在小数据集上,GRU 的简化结构可能比 LSTM 泛化能力更强。
---
### **总结**
GRU 的核心价值在于**高效捕捉序列中的短期和长期依赖关系**,适用于几乎所有需要建模时间或顺序数据的领域。实际应用中,通常与注意力机制(Attention)、Transformer 等结合使用以进一步提升性能。